How Rippling builds enterprise-grade APIs

As Rippling has expanded our customer base and moved upmarket, we have prioritized delivering advanced and flexible integration capabilities to meet the evolving needs of our customers. Our enterprise-grade APIs empower customers to integrate with Rippling seamlessly from their own infrastructure, enabling faster implementation with minimal engineering effort. These APIs play a pivotal role in driving the success of our customers by enhancing their operational efficiency and unlocking strategic opportunities.
Good APIs don’t just happen; instead, they require a thoughtful design process that incorporates a full set of robust features, adherence to industry standards and best practices, and a focus on usability to ensure seamless integrations.
This article will focus on how we build Rippling’s enterprise-grade APIs: the problems we’ve encountered, the decisions we’ve made, the best practices we followed and the lessons we learned throughout the process.
API Design Principles
In designing our APIs, we adhered to a set of carefully considered principles to ensure clarity, consistency, and ease of use for our customers. These principles were developed based on industry best practices and a detailed comparative analysis of public APIs from leading technology companies. You can explore the details and specific implementations in our API documentation.
Here are the key principles we adopted:
- RESTful design: We chose REST (Representational State Transfer) as the architectural style for its simplicity, scalability, and widespread adoption across the industry.
- Plural nouns for resources: Resource endpoints are named using plural nouns (e.g., /workers, /users) to align with the concept of collections in REST APIs and to maintain consistency across endpoints.
- However one such example is our sso-me endpoint. Unlike most of our endpoints, which use plural nouns, this endpoint is singular. It is designed to return information specific to the company making the API call. The singular naming reflects the endpoint’s purpose: it’s not querying a collection of resources but instead providing focused, contextual information directly tied to the caller’s identity.
- Lower kebab-case for URL paths: We didn’t see consensus among other public APIs but we chose kebab-case as it typically looks clearer and less cluttered (than camelCase), is easier to type and recognize (than snake_case, which requires the use of the Shift key and has the underscore which might be mistaken for space).
- Lower snake_case for URL parameters and fields: It’s more natural to use snake_case for the JSON fields in the payload or the field in the query parameter given that Rippling uses Python extensively as its backend programming language.
- All date fields must be in UTC in ISO8601 format: To ensure consistency and interoperability, all dates in our APIs are formatted in UTC using the ISO 8601 standard. This widely accepted format allows developers to easily work with date and time values across different systems and time zones.
- Avoid using verbs in the endpoint: In keeping with RESTful design principles, we avoid using verbs in API endpoints unless it’s impossible to express the action using standard REST semantics. This approach emphasizes resources over actions, maintaining clarity and consistency in endpoint design.
- Dedicated domain for the APIs: we decided to host the production REST APIs via a dedicated domain called https://rest.ripplingapis.com/ and set up separate domains for each non-prod environment, e.g. https://rest.ripplingsandboxapis.com/ for the sandbox environment. This solved a number of issues for us:
- API traffic is isolated at the domain-level.
- Routing is unambiguous, and cookie state doesn’t transfer between different environments.
- Each domain will be administered separately from CloudFlare so that we can have proper environments and develop tooling to promote changes from test to prod domains.
We believe having the API standards defined and enforced at the platform level gives our customers consistent behavior across APIs, which should ease their efforts and avoid confusion when integrating with Rippling APIs as a whole.
Next up, let’s talk about the feature set we developed for our enterprise-grade APIs.
Pagination
Pagination is crucial for Rippling APIs because it ensures efficient data handling, improved performance, and a seamless user experience. By dividing large datasets into smaller, manageable chunks, pagination reduces the strain on server resources, minimizes network bandwidth usage, and enables faster response times. It also gives more control to the API consumer to decide the size of the data they want to retrieve and the pace of the retrieval.
We built support for pagination as a platform capability with consistent default behaviors enforced:
- List APIs will always be paginated.
- Pagination shall be cursor based, with support for limit and cursor parameters.
- The API response contains the next_link to store the url to hit for getting the next page response and the results field containing the list of serialized results. For example:
- “next_link”: “/example-data?limit=100&cursor=dXNlcjpVMEc5V0ZYTlo&order_by=field1+desc,field2”
- "results": [{“name”: “Adam”}, {“name”: “Eve”}, … ]
- The default value for the limit is 50 and the maximum value is 100 but it could be customized at the API level if a larger maximum value is needed.
Why cursor based pagination
There are usually two paradigms for pagination APIs:
- Offset-Limit Pagination: This is a common method where data is fetched in pages based on two parameters - offset (indicating where to start fetching data) and limit (how many records to fetch). While straightforward, it can become inefficient with large datasets, as the database needs to count and skip over offset records before fetching the desired limit of records.
- Cursor-Based Pagination: In contrast, cursor-based pagination uses a cursor to keep track of where the last page ended. It fetches records starting directly after the cursor, making it more efficient for large datasets. It also avoids issues like skipping or repeating records when data is added or removed during pagination.
Given the efficiency and consistency advantages of cursor-based pagination, especially in large datasets, we decided to use cursor-based pagination. It negates the need to scan through previous records, using a unique cursor that serves as a bookmark for fetching records.
API Versioning
Unlike some APIs that embed the version number in the URL (e.g., /v1), we chose a header-based versioning approach. This allows customers to retain the same URL path while testing different API versions simply by modifying the header(e.g., Rippling-Api-Version: 2023-08-01). Furthermore, we let customers specify a default version when creating the API token. In case no version is specified in the header, we serve the request with the default version associated with the token rather than serving with the latest version. In this way, we protect our customers from unexpected changes as newer versions of the API are released. This design prioritizes flexibility and stability, ensuring a seamless and predictable experience for our customers.
We introduced an innovative approach to supporting API versioning at the platform level: for all the APIs, we require a dedicated DTO (Data Transfer Object) to represent the fields and the type of each field. This encapsulation ensures that we don’t directly expose any details in our backend data model and it also provides the basis for us to annotate versioning info. We developed annotation-based API versioning to simplify the implementation and to also guarantee the consistency across APIs.
Viewset-Level Versioning
Many of Rippling's backend API are built on top of the Django REST Framework (DRF), an extension of Django for building RESTful APIs. It helps to structure API endpoints (i.e., "views") and the "viewset" functionality is particularly useful: a ViewSet class allows us to combine the logic for a set of related views in a single class and it automatically generates "get", "list", "create", etc. endpoints for the particular resource type.
Our versioning approach controls the entire lifecycle of a viewset. It is particularly useful when introducing or phasing out collections of endpoints in sync with the API's version progression.
1
2
3
4
5
6
7
@versioned_viewset(
introduced_in=versions.VERSION_2023_01_01,
deprecated_in=versions.VERSION_2023_01_06,
removed_in=versions.VERSION_2023_01_08,
)
class PrototypesAPIViewSet(PlatformAPIBaseVersionedViewSet):
...In the example provided, the lifecycle of PrototypesAPIViewSet unfolds as follows:
- Introduction: It is introduced and made available starting with version “2023-01-01”. When a new viewset is introduced, it makes all the CRUD operations available for the particular resource type, unless explicitly overridden by the view level annotation.
- Deprecation Notice: In version “2023-01-06”, it is marked as deprecated. This serves as a notification of impending removal, urging users to begin transitioning away from it.
- Removal: From version “2023-01-08” onward, it is removed and ceases to be accessible.
This sequential approach ensures that both developers and users are well-informed about the viewset’s availability timeline, as well as the necessary steps to prepare for its deprecation and eventual removal.
Endpoint-Level Versioning
Endpoint-level versioning provides granular control over the version lifecycle of individual API endpoints within a viewset. This facilitates the ability to assign distinct versioning parameters to specific endpoints, separate from the viewset's overall versioning framework.
This level of granularity is ideal for situations where only certain operations or endpoints within a viewset need to be version-managed due to specific functional or business requirements.
1
2
3
4
5
6
7
8
9
class PrototypesAPIViewSet(PlatformAPIBaseVersionedViewSet):
@versioned_view(
introduced_in=versions.VERSION_2023_01_01,
deprecated_in=versions.VERSION_2023_01_06,
removed_in=versions.VERSION_2023_01_08,
)
def list(self, request: Request, *args: Any, **kwargs: Any) -> Response:
...
As an example, within the PrototypesAPIViewSet, the list endpoint employs endpoint-level versioning marked by the @versioned_view decorator:
- Introduction: The endpoint becomes accessible starting with version “2023-01-01”.
- Deprecation Notice: It is flagged for deprecation in version “2023-01-06”, signaling that the endpoint will soon be phased out.
- Removal: Starting with version “2023-01-08”, it is removed and will no longer be available for use.
This approach to endpoint-level versioning ensures that developers can manage the lifecycle of specific endpoints more effectively and that users are informed in advance about any upcoming changes affecting endpoint availability.
Field-Level Versioning
Field-level versioning provides the most granular control over each individual field within an endpoint. Besides the addition and removal updates, the field-level versioning facilitates more updates like changing an optional field to be required, changing the description of the field, changing the default value for this field, etc.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class Prototype(BaseResourceDTO):
...
photo: str | None = FieldMetadata(
description="URL address for the employee profile picture.",
deprecated=True,
removed=True,
required=True,
version_changes=[
IntroducedIn(versions.VERSION_2023_01_02),
UpdatedIn(
versions.VERSION_2023_01_03,
required=StateChange(from_val=False, to_val=True),
),
UpdatedIn(
versions.VERSION_2023_01_04,
description=StateChange(
from_val="Employee profile picture",
to_val="URL address for the employee profile picture",
),
),
DeprecatedIn(versions.VERSION_2023_01_05),
RemovedIn(versions.VERSION_2023_01_06),
],
)
...
Here's a breakdown of the @version_changes list for the photo field in the Prototype model:
- It was first introduced in version 2023-01-02, making it available for API consumers.
- It was changed from optional to required starting from version 2023-01-03.
- Its description was updated starting from version 2023-01-04.
- Starting with version 2023-01-05, the API starts signaling that the photo field is on its way to obsolescence and advises consumers to transition away from its use.
- Starting with version 2023-01-06, it is officially retired from the API with this version, and it is no longer available for use.
With the sophisticated support for versioning at different levels, each product team can roll out different versions of their APIs with ease. With the versioning supported at the platform level, we are able to automate API specs generation for different API versions, conduct data serialization adaptively according to the API version, and provide a consistent experience for customers when interacting with different versions of the API.
API Documentation
Our API documentation is designed to be not only accurate but also intuitive and accessible. To achieve this, we adaptively generate OpenAPI specifications directly from the DTO (Data Transfer Object) class definitions and versioning annotations. We then convert these specs to human-readable documentation pages for display in the developer.rippling.com site. This automated approach ensures that the documentation remains consistent with the underlying API implementation and reflects the latest changes without manual intervention.
Key features of our API documentation:
- Automated specification generation:
- We use a Python script to parse the DTO class definitions and associated annotations to dynamically generate OpenAPI specs. We leverage the apispec library under the hood to make sure the generated specs are following the Open API standards.
- The annotations dictate field attributes such as:
- Existence in a particular version of the API
- Name of the field
- Description of the field
- Whether the field is required or not
- Whether the field is expandable or not
- Whether the field is read-only or not
- Whether the field can be used for filtering
- Whether the field can be used for sorting
- Hosted Platform:
- The documentation is hosted on a dedicated website, providing customers with the ability to download the specs in OpenAPI format and try out the APIs with sample requests directly from the website.
- The website also supports searching functionality to quickly navigate to the APIs of your interest.
With this adaptive, script-driven documentation approach we believe our customers will always have access to the most reliable and interactive API reference, reducing integration time and enhancing developer productivity.
Field Expansion
Our field expansion feature meets the need for seamless navigation and data retrieval when dealing with interconnected resources. Many of our customers require not only the primary resource details but also related data represented by nested or referenced fields. Instead of making multiple additional API calls to retrieve the associated resources, field expansion allows them to expand specific fields inline, simplifying workflows and reducing latency. For example, suppose that you're querying for a list of workers, and you want information about each department that they're in. Field expansion allows you to get full department info as part of the "get workers" request instead of making a separate API call for these after the first one. This feature enables API consumers to efficiently access complex, interconnected data structures while minimizing the overhead of additional requests.
Rippling API consumers can expand field(s) in a Get or List response using the expand query parameter:
- We support up to 10 fields in the expand query parameter, e.g. ?expand=employment_type,level,department would have the employment_type, level and department field expanded in the response.
- We support up to 2 levels of nested field expansion, e.g. ?expand=manager,manager.level would have the level field inside the manager field expanded in the response.
- We support field expansion for list fields as well, e.g. ?expand=teams would have all the associated teams for each individual employee expanded in the response.
The N+1 Query Problem
We will run into the classic n+1 query problem if we try to query for the referenced fields one-by-one when looping through the list of records. So instead of doing the DB query for each individual record, we batch load the referenced fields for all the records once and then assign them back to each record. We worked around this problem at the platform level: each product team only needs to annotate the fields that are expandable in their API’s corresponding DTO and we do the field expansion based on what’s specified in the API request. In this way, not only does it simplify the implementation of the expansion, but we can also apply consistent access control at the platform level for the fields that get expanded.
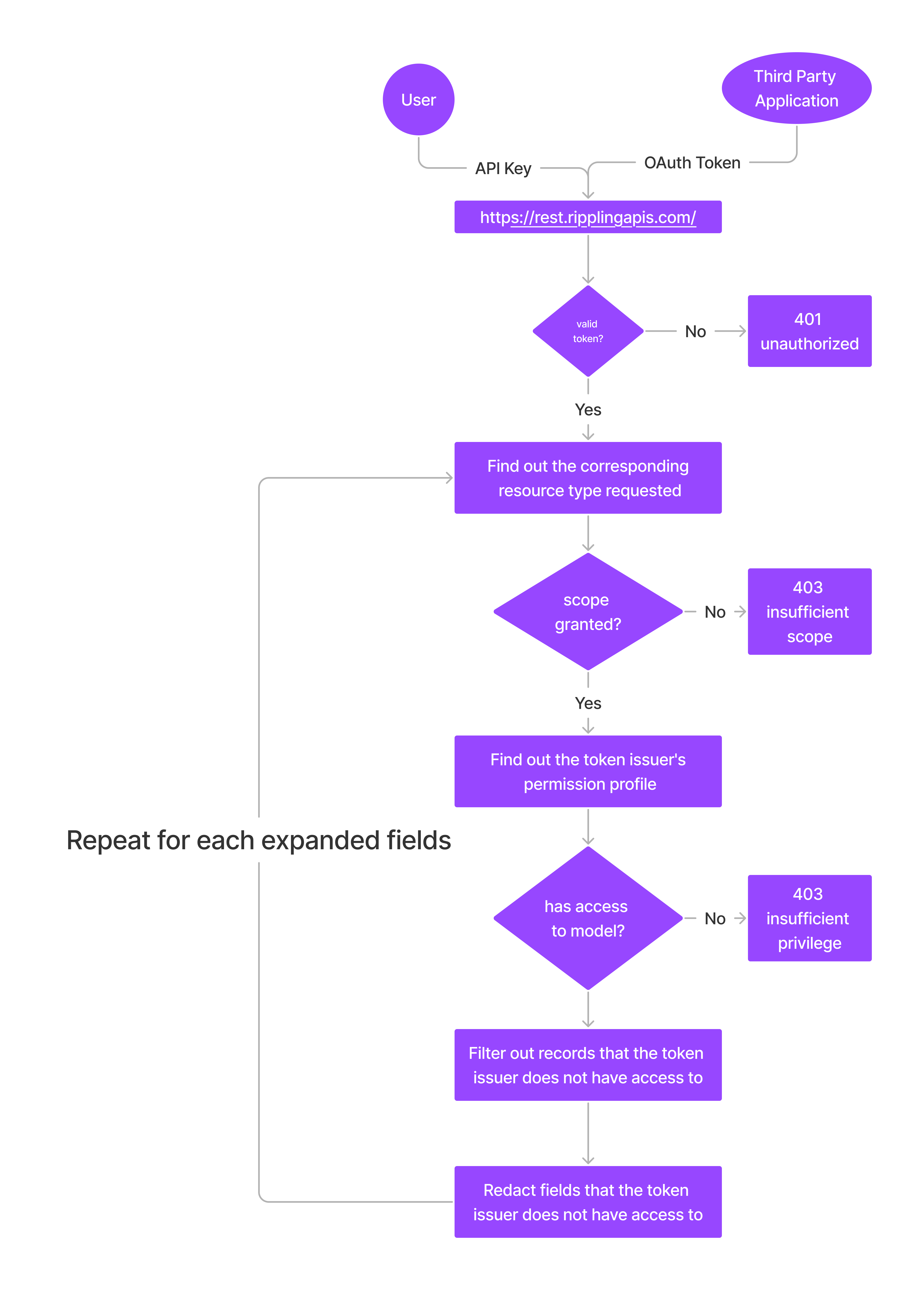
Access Control
Rippling APIs can handle sensitive personal information so we must have a rigorous access control mechanism to protect our customers’ data. We intentionally use the same permission system that is used by the Rippling web application for the API platform so that we keep consistent data access between the web application and the APIs.
Each Rippling API is tied up with a concrete resource type (e.g., worker, user, department) and we use the access token scope to control what resource types the caller is able to access. Scopes usually follow the {full_resource_name}.{read|write} name convention. When people create an API token or issue an OAuth token for the third party application, they can only grant scopes that they have access to based on their permission profile. When the API consumer makes API calls, they should only be able to access resource types that they are granted access to, otherwise they will get permission denied.
Besides using scopes to control the access to resource types, we also apply more granular access control on the individual resource (e.g. the API token might only be able to access information for people who report to the API token issuer) and specific fields of the resource (e.g. the API might only be able to access the fields with basic data classification rather than sensitive data classification). When people have access to a particular resource but not all the fields of the resource, the inaccessible fields are redacted in the response.
It’s worth noting that the same access control is applied when people expand fields which represent another resource.
Here is the sequence of data access controls we have in place when serving a particular request:
Conclusion
Building enterprise-grade APIs is about more than just functionality - it’s about delivering robust, scalable, and flexible solutions that address real-world business needs. Our journey has been driven by a deep understanding of our customers’ challenges, enabling us to design APIs that not only integrate seamlessly into diverse ecosystems but also empower innovation. As we continue to evolve, our focus remains on creating APIs that set the standard for reliability, performance, and adaptability, ensuring our customers can build with confidence and achieve their goals. To explore our APIs in detail and see how they can power your applications, visit https://developer.rippling.com/documentation/rest-api.

This blog is based on information available to Rippling as of December 26, 2024.
Disclaimer: Rippling and its affiliates do not provide tax, accounting, or legal advice. This material has been prepared for informational purposes only, and is not intended to provide or be relied on for tax, accounting, or legal advice. You should consult your own tax, accounting, and legal advisors before engaging in any related activities or transactions.






