Suspend-unaware cross-platform monotonic time in Rust

Rippling IT is one of the core business suites at Rippling, allowing customers to manage their company’s devices while providing seamless identity management for employees to access third-party online services. Within IT, device management consists of a management dashboard, a desktop client, and a background agent that runs on all of the laptops managed by Rippling customers. The agent is written in Rust and runs many jobs on a recurring schedule such as uploading logs, checking for updates, and synchronizing device hardware information with Rippling.
An important requirement of the agent is that it has a low resource impact on client hardware. As such, one metric we monitor closely is the duration of the jobs we run, including those listed above. This is important to make sure jobs are not timing out and taking up too many resources on a managed device. Originally Rust’s high resolution time API, Instant, was used by calling Instant::now() and then upon completion, Instant::elapsed() to measure the duration of a task.
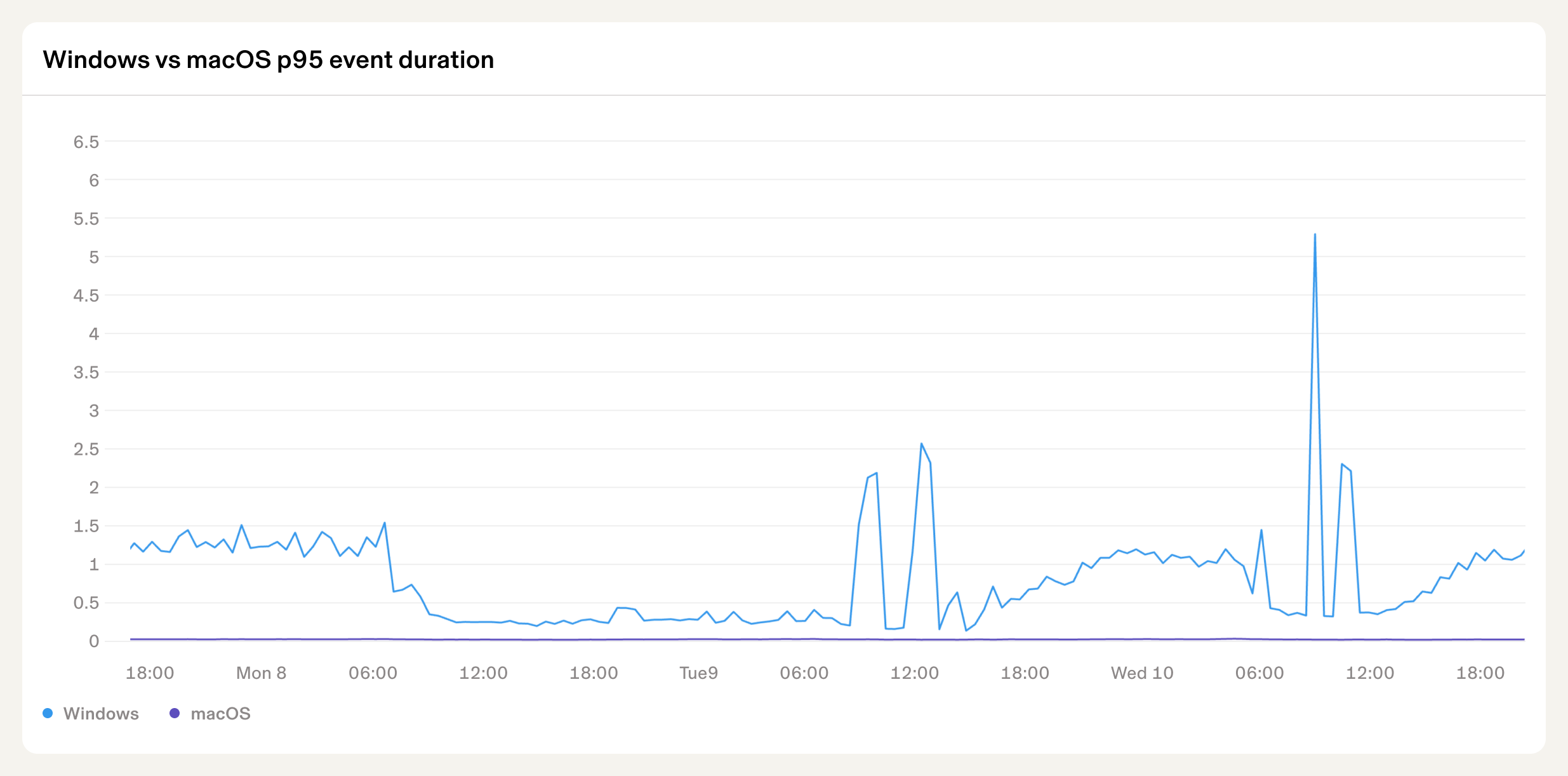
However, we saw a problem arise when we inspected the job durations on different platforms. Looking at the graph below, why do Windows machines take longer and have erratic durations when completing tasks while macOS durations are consistently lower?
Hard Software Problems: Time
If you peek at the code for Rust’s Instant API, you will find that it is mostly a cross platform wrapper around polling the system’s monotonic clock. This clock is naturally different on different operating systems. Tracing through the OS specific implementations we can find an explanation for the different behavior: on Windows machines the clock that is polled still ticks while the system is asleep. Aha!
By default when a Windows laptop’s lid is closed, it runs for 300 minutes. After that point memory is swapped to disk and the computer shuts down to save battery. This is called “system suspension”. When the laptop is reopened the pages are pulled from the disk and the computer continues to execute. The issue here is that time has passed on the wall clock, but relative to the system itself, no time has passed since it has been asleep. When a system observes time passing while it is suspended, we call it “suspend-aware”. For our time library, we want time to be “suspend-unaware”. On macOS the Instant API does not allow time to tick while the computer sleeps (suspend-unaware), but on Windows it does (suspend-aware). This inconsistency in the Rust standard library is what lies at the core of this issue. In fact, this issue is known and documented but still not consistent across platforms.
Upon testing we were able to reproduce this issue by forcing system hibernation in Windows (instead of waiting 300 minutes!). Our theory was that these suspensions, in conjunction with the standard library issues, were the cause of these spikes. Additionally we observed many timeouts on windows, which we accredited to our use of Tokio’s asynchronous timeout function, which is also based on std’s Instant. Injecting changes to fix the standard library and Tokio would have required forking each respective library, so we opted to write our own time library in Rust to solve this issue and standardize the behavior across platforms!
Selecting a Time Source: Monotonic time
There are different notions of time in software engineering. There is the time that you see on your clock that your computer displays which is regularly sync’d. Think of when you click the “automatically set date and time” checkbox when you set up a computer. Even if your machine is off for days, it will update to the correct time within moments of turning it on. How does this happen? As it turns out, there is an entire time protocol called NTP that is used for synchronizing clocks across different locations in the world. There are source clocks which transmit their time measurements to a tree of servers. As the time readings go through network hops, NTP accounts for the latency of the transmission to update the readings once they are finally read off the network buffer on the destination systems. These source clocks are often extremely precise atomic clocks in satellites orbiting earth.
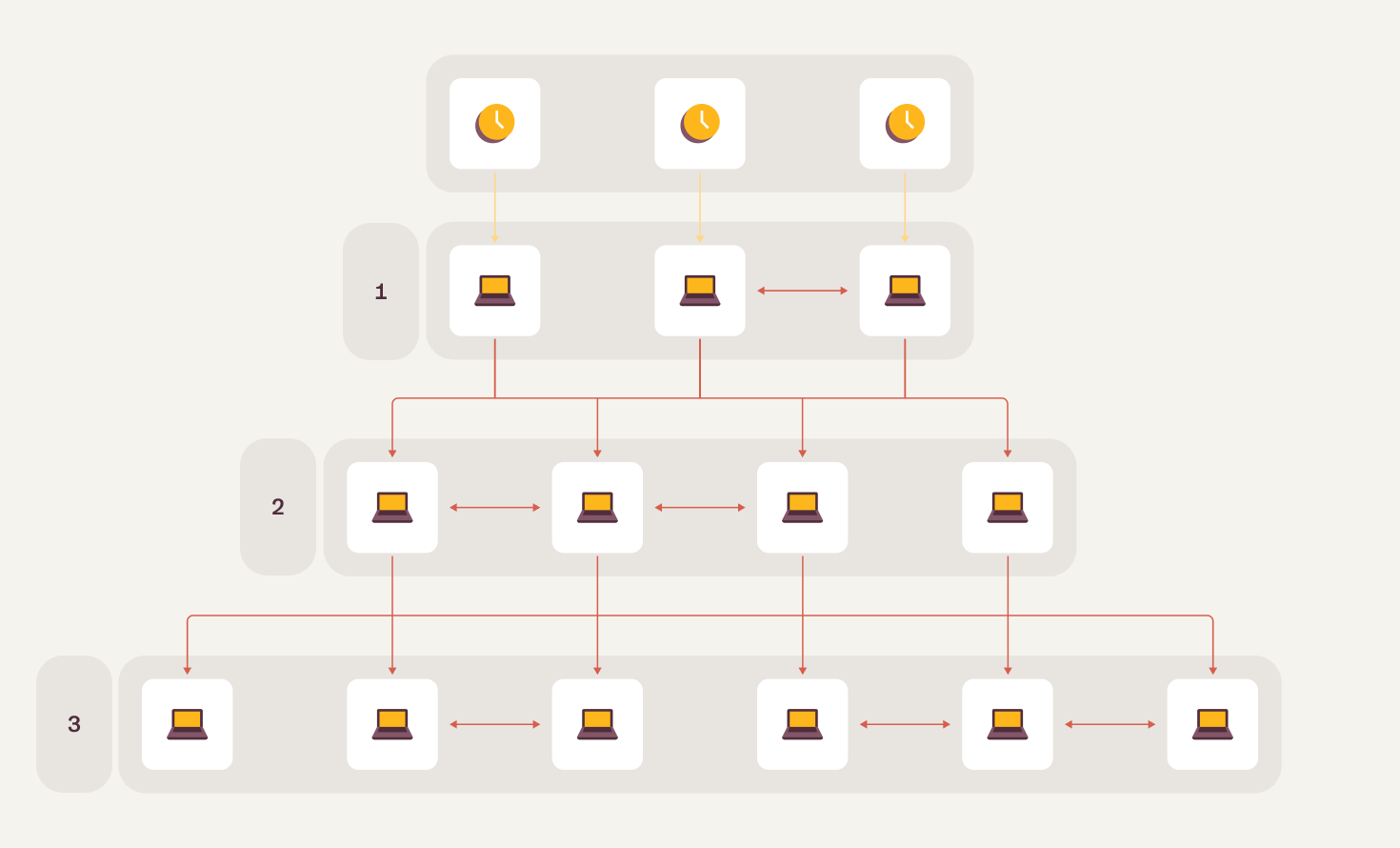
What can be problematic about synchronized time measurements is that due to the drift of the system’s internal clock, time can actually jump forwards and backwards when it is synchronized with the source clock. This can produce indiscriminate data when we are measuring the distance between two points of time on a system relative to itself. This problem is most acutely felt over short periods of time since clock drift is usually on the order of seconds and thus the jumps will be in seconds as well.
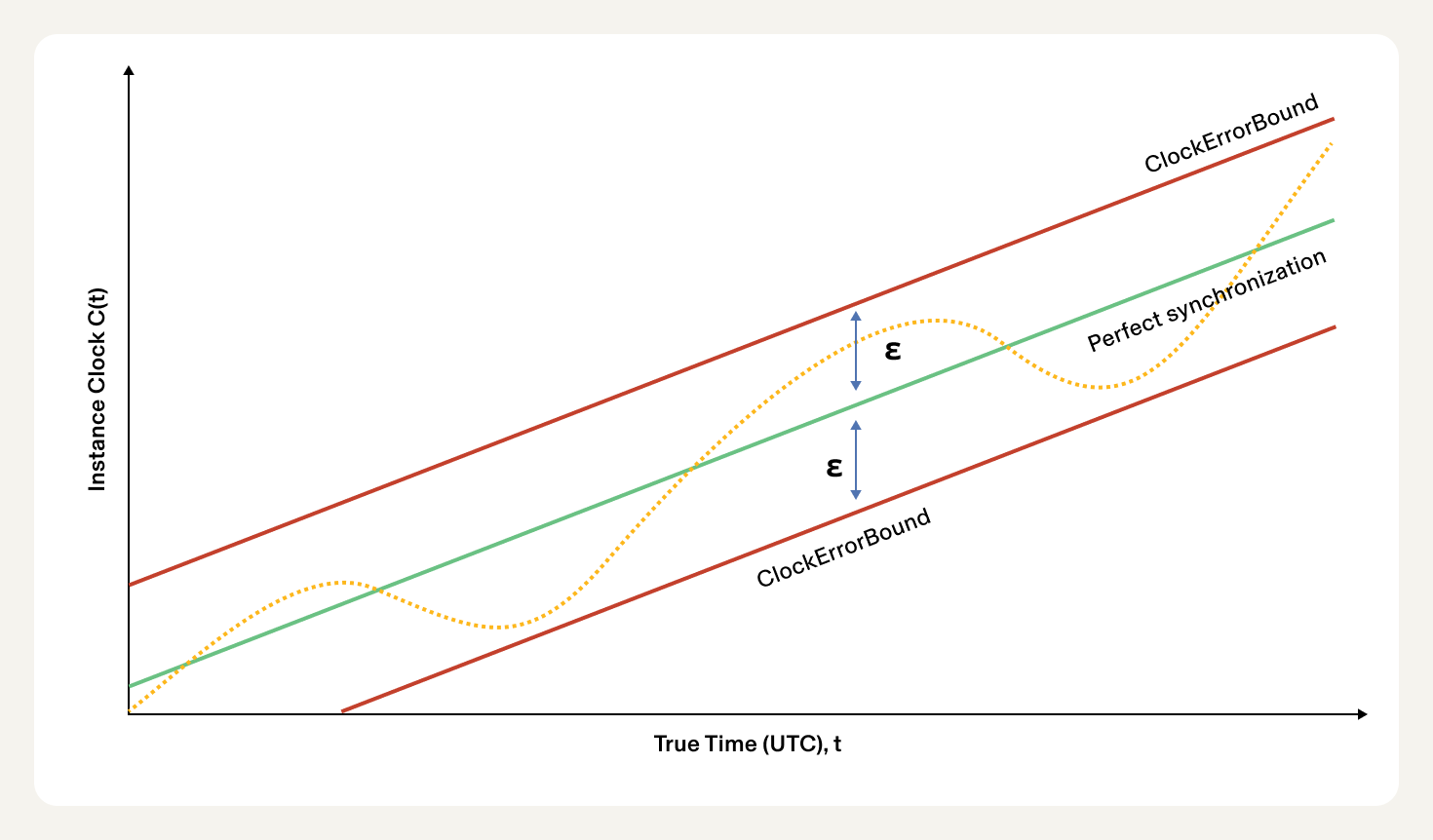
Because of this, there is another type of clock on every system called the “monotonic clock”. This clock’s time measurements always increase, however they may drift from the global standard of time. As such, these measurements are more suited to short term and precise time measurements. The Rust Instant API polls each system’s monotonic clock, although in different ways depending on the platform the code is being run on. In order to consistently be “suspend unaware”, we need to poll a monotonic clock that does not increase while the system is asleep.
On macOS this is easy, as it is clearly documented in the clock man page for macOS. We simply poll the CLOCK_UPTIME_RAW clock using the clock_gettime(...) syscall. On Windows it is a little different. To query different clocks you must use different syscalls which requires writing a syscall wrapper. The Rust 1.77 standard library uses the QueryPerformanceCounter syscall for its Instant::now() time measurement, which is suspend-aware. After some research we found QueryUnbiasedInterruptTimePrecise which provides a monotonic performance counter that is suspend-unaware. If there were not a syscall like this, we would need to keep track of the system suspend state in a fault-tolerant way and perhaps even an internal time representation. This would quickly get messy – especially on agent failures and restarts.
By writing a custom time library this clock behavior can be unified and the different syscalls can be abstracted away into a common, opaque, time API. Even better – we can merge this back into the Rust ecosystem and contribute to open source.
Implementation: Suspend-Time
We developed the library suspend-time to solve these issues and it is available on crates.io and GitHub! It also has public documentation – take a look at the examples on any of these pages to get started using it.
For implementation hints, we looked at the standard library for inspiration. In the Rust 1.77 standard library for each Instant there is an internal member of the type Timespec. A Timespec is a platform-specific representation of time that can be different for different operating systems. When a build is created there are macros to detect the target platform. That code is pulled into the build to poll the underlying syscalls in either Windows or macOS and store the results in a Timespec. One thing we didn’t like about this implementation was the duplication of operator logic for each platform. While it is true that there are different clock formats on different platforms, for our purposes we do not need to keep the clock measurements in their native format. It also helps that Rippling restricts its device support to Windows and macOS exclusively, instead of the rest of the unix and linux platforms Rust attempts to support.
For our approach we opted for a schema similar to the std::time::Duration type that Rust uses to represent time.
1
2
3
4
pub struct SuspendUnawareInstant {
secs: u64,
nanos: u32,
}On top of storing time in a standardized format across platforms, we also implemented the difference and addition operators ourselves so we could control overflows and panics. This is because the Duration type in the standard library panics on overflows and underflows, which is a behavior we wanted to avoid in the Rippling agent. Standard library Instants also exhibited this behavior. Instead, our library has a set of invariants for its inputs and will floor to 0 upon violation of those invariants. This way we can fix issues and edge cases without service disruption. For example, when an Instant in the future is subtracted from an Instant in the past, Rust panics. For our SuspendUnawareInstant it simply returns a Duration of 0. Additionally, when polling the system clock there are edge cases on platforms like macOS. For certain times macOS actually returns negative numbers which are then adjusted in the Unix Timespec methods. Since we are polling a performance counter we assume the result to always be positive, but on the off chance that it is negative, we floor to zero and return.
Another interesting implementation detail was dealing with asynchronous traits in Rust, specifically for Futures. Tokio has a timeout(...) function as well as a Sleep struct. The actual implementation within Tokio is quite interesting: It is a bucketed time wheel that is continually stepped through such that the system clock is polled minimally and there are minimal interrupts. Every time you create a timeout in Tokio, it creates an underlying Sleep which registers itself to one of the time buckets in the main Tokio engine and then yields to the scheduler. Once time reaches its bucket, it will be woken up.
One issue with Tokio timeouts and sleeps is that they are based on Instant at their base layer which, as described previously, is suspend-aware on Windows. This means when a Tokio timeout is running and a user closes their laptop, that task will time out when it shouldn’t. This can lead to mass timeouts when employees go to lunch or close their laptops over the weekend. As such, we reimplemented a timeout function along with an underlying suspend_time::sleep(...) async function in the suspend-time library.
Originally we used threads for this implementation following the basic example laid out in the Tokio documentation. Essentially the task spawns a thread that calls to the Future’s waker once the correct duration has elapsed. However, the overhead of spawning threads turned out to be a performance issue in the agent, eventually causing Tokio to crash. To improve on this we opted to re-use the bucketed time wheel Tokio implementation of timeouts. This way there is only one source of time and wakers are only used when it is time for a task to be woken up. We added an additional check to determine if the correct amount of time had passed based on SuspendUnawareInstant. If not, the suspend_time::sleep future will go back to sleep, registering itself to the time wheel. Using this method we observed a 50x speedup over the thread-based solution while also greatly simplifying the code! It’s always nice when you can improve performance and reduce the lines of code in a project. I highly recommend checking out the PR that solved this issue.
Validating Critical Timing Behavior
Due to this library’s integral role in the agent it was important for it to be thoroughly tested for the correct behavior. For this we used a combination of integration tests on both SuspendUnawareInstant and SuspendUnwareSleep, as well as direct table testing on the internal behavior of the SuspendUnawareInstant type. The table testing was extremely helpful since we could modify the internal (and unified) time representations of the SuspendUnawareInstant to ensure that even in undefined scenarios we behave in a predictable way. Having a unified in-memory representation of time, unlike the standard library, allowed us to easily test edge cases in a clear way with minimal code.
Results
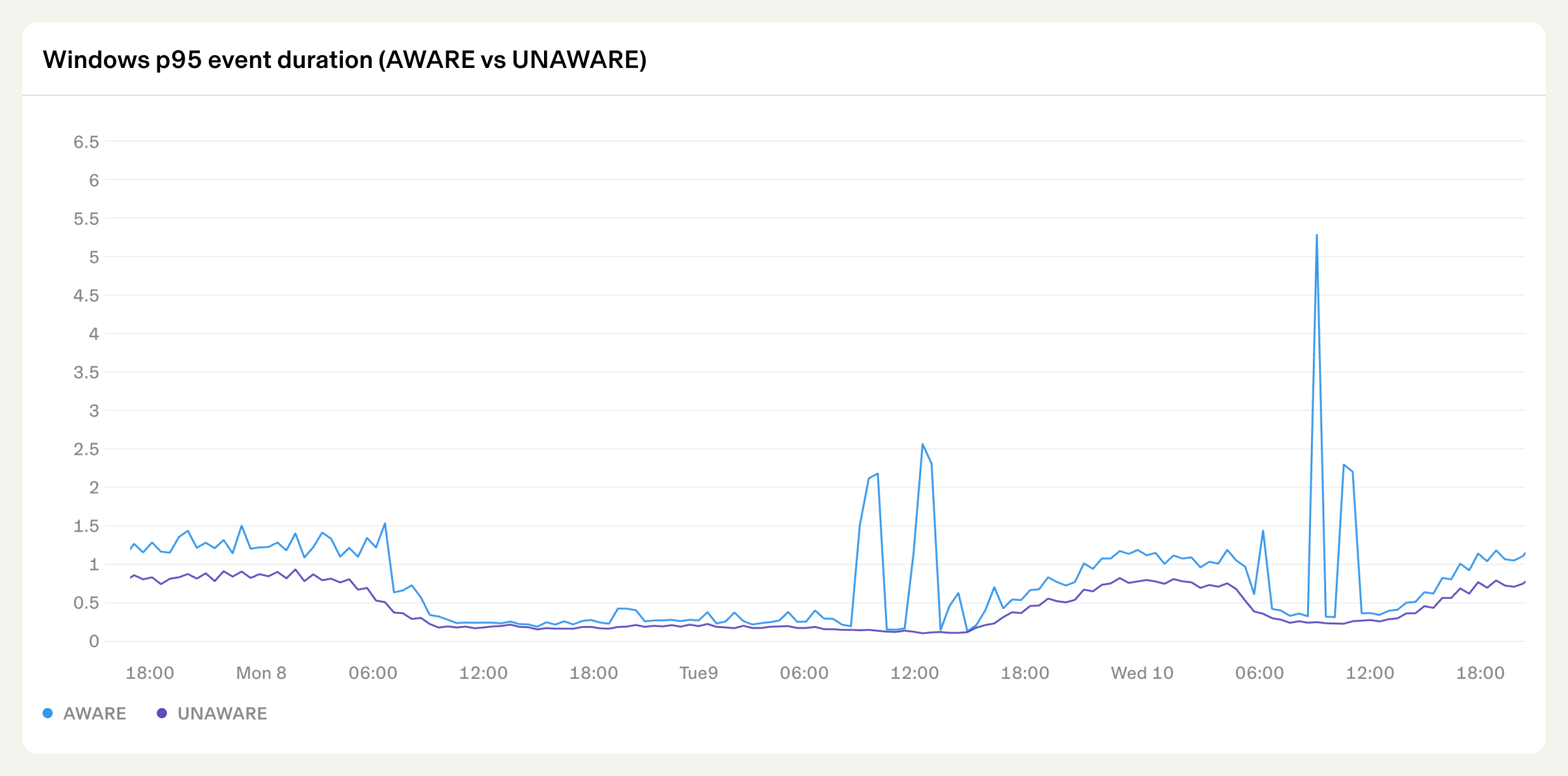
Once the library was finally written and tested, we deployed it in a new release of the agent. The results were great! There were no more spikes and it was very obvious when the suspensions were occurring. The team finally could have proper visibility into task durations as well, since the old task durations were polluted with increased values that bumped up the rolling averages of task durations.
Rippling's agent runs on tens of thousands of devices around the world. Measuring how long agent tasks take is a small feature, but extremely important for ensuring that we're not slowing down our customers in their day-to-day work. This project fixed our metrics and also allowed us to contribute back to the Rust ecosystem to help others dealing with similar issues.









